Using symbolic logic for mitigating nondeterministic behavior and hallucinations of LLMs

If you want an automated system to follow a given set of rules reliably, no matter how complex they are, symbolic logic is the perfect fit for the job. In particular, default logic is well suited when translating experts’ knowledge into machine-readable definitions since it closely relates to how humans describe real-world rules. Unfortunately, these systems are not well suited to be used by humans, especially when not trained to use logical programs.
This is where LLMs come in: They (kind of) understand what the user means, no matter if they could use the exact correct terms or descriptions. On the other hand, LLMs have problems reliably following rules, especially if these become more complex, and are prone to hallucinations, especially during more extended conversations.
To mitigate the downside of both approaches, we started experimenting with combining them, letting each approach shine where it is best.
A chatbot for professional caretakers
The scenario is the professional caretaker situation in a hospital, where the system is located in an (audio) chatbot, sitting at each patient’s bed. Proper documentation in this scenario represents a considerable challenge due to usually being done after the actual work on the patient, with little to no time. In addition, a lot of background knowledge in the medical field and about the concrete case is needed to decide on the next steps sensibly and to notice possible critical derived problems.
The bot should listen to what is said during the work, update its current beliefs of the patient’s status, and use its medical background knowledge to derive additional information to generate warnings for situations a professional caretaker might overlook.

In this scenario, we have a patient who had surgery three days ago. The patient is well, but then her temperature is rising. While this might be okay in other situations, after surgery, it might indicate complications due to the surgery or the anesthetics used.
This warning should be reliably derived from the given input, so this part is what is done in a logical program, not the LLM itself.
Generic approach
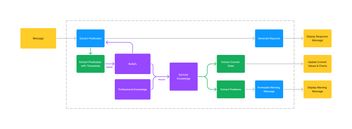
The overall system has three tasks when reacting to a message from a user:
- Generate a written response representing what the system understood, as direct feedback to the user, as an additional and immediate validation if everything went right.
- Generate a written warning in addition to the text response when its derived knowledge contains a new problem that might require the user's attention.
- Provide a representation of the updated, derived knowledge state, i.e., used to update tables and charts.
To achieve this, we combine LLMs, in this example via the OpenAI API using a gpt-3.5-turbo model, with logical programs, in this example, by using the answer set solver DLV.
Predicate extraction
To extract logic predicates from a written or spoken user message, we instruct GPT to extract logic predicates, allowing only a very limited set of predicates.
prologI want you to extract logical predicates from user input.
Only extract predicates, do not write anything else, no explanation, no excuse.
Use only the limited alphabet, nothing else, do not extend the alphabet:
START
data(temperature, TEMP). with TEMP integer between 30 and 45
data(painLevel, LEVEL). with LEVEL integer between 0 (no pain) and 5 (severe pain)
condition(stability, STABILITY). with STABILITY in [stable, unstable]
condition(backgroundInfo, INFO). with INFO [surgery, operation, procedure, allergic]
[...]
END
This is the text to extract predicates from:
START
#{message}
ENDFor the first message in the above example, the answer from GPT might look as follows:
prologdata(temperature, 37)
condition(stability, stable)
condition(backgroundInfo, surgery)In order to be able to keep track of the patient and react to changes over time, we need to add an explicit representation of time to the predicates. We do this by adding a timestamp to all predicates received from the LLM, and adding the timestamp itself to the agent’s beliefs.
prologtimeStamp(1).
data(temperature, 37, 1).
condition(stability, stable, 1).
condition(backgroundInfo, surgery, 1).These transformed predicates are then added to the beliefs of the agent.
Deriving knowledge
To derive new knowledge based on the agent’s current beliefs and background knowledge, we use an answer set solver, in this case DLV. First, we give the agent an understanding of time and how to derive current values.
prolognewerTimestamp(T) :- timeStamp(T), timeStamp(T2), T < T2.
currentTimeStamp(T) :- timeStamp(T), not newerTimestamp(T).
newerData(TYPE, T) :- data(TYPE, _, T), data(TYPE, _, T2) , T < T2.
dataBetween(TYPE, T1, T2) :- data(TYPE, _, T1), data(TYPE, _, T2), data(TYPE, _, T3), T1 > T3, T3 > T2.
currentData(TYPE, VALUE) :- data(TYPE, VALUE, T), not newerData(TYPE, T).
[...]We now can use this knowledge to derive information about possible problems, in this example related to rising temperature after a surgery, due to the possible use of anesthetics.
prologanesthetics :- backgroundInfo(surgery).
anesthetics :- backgroundInfo(operation).
[...]
currentProblem(T1, risingTemperatureAfterOperation) :- data(temperature, X1, T1), data(temperature, X2, T2), anesthetics, X1 > X2, T1 > T2, not dataBetween(temperature, T1, T2), not newerData(temperature, T1).Note that in this case, we derive the information about possible problems from the use of anesthetics. In a real live, more complex scenario, there might be a lot of other reasons that may have caused the administration of anesthetics, which might trigger the same warning. This derived knowledge is called the epistemic state of the agent.
Fighting hallucinations
In addition to deterministically applying rules, we aimed to fight hallucinations in possibly long running conversations with the agent. To achieve this, we do not provide the conversation history in the API call but extract all current beliefs regarding data from the agent’s epistemic state and add it to the prompt, leaving out background information and derived problems. In the above example, we would fill in the current part:
prologYou can use the following background information:
START
data(temperature,37)
condition(stability,stable)
ENDGenerating output
In the last step, we generate the agent’s output.
For generating the written response in the conversation, we ask the LLM to generate a brief confirmation on the predicates it detected, feeding it it’s previous response.
prologConfirm briefly and short the updates to a patient's file based on the following logic predicates:
data(temperature, 37)
condition(stability, stable)
condition(backgroundInfo, surgery)We extract all data points, background information, and derived problems from the agent’s epistemic state to provide the actual data. It can be used to fill tables, charts, or journals of the professional caretaker.
In case a problem is detected, we use the LLM to generate a written warning in addition to the ‘raw’ predicate in the data output:
prologAct as a warning system for professional caretakers. Generate a concise warning explanation for the following problem:
currentProblem(risingTemperatureAfterOperation)Conclusion
While it is possible to mitigate the downsides of both approaches to some extent, this work only features as a proof of concept and still leaves a lot of work to be done.
Although the answer set solver works reliably, it depends on the correct transformation of user input to predicates. While this worked surprisingly well with GPT and Bard in our tests, both systems did not reliably stick to the limited alphabet. We tried to mitigate this problem by explaining to the LLM how to deal with uncertain transformations to keep the derived data clean and allow the system to display what part was not understood, allowing the user to react and refine the input.
In addition, for generating reliable problem descriptions, the LLM should be fine-tuned or provided with expert knowledge with a lang-chain approach to ensure the generated warnings make sense.
However, this represents an exciting approach that we will continue to pursue in our internal research and projects that rely on reliable rule adherence.
Do you have a project that would benefit from a better interface that still reliably fits within the processes? Don't hesitate to get in touch with us.
Many thanks to Nils Binder for styling the example application and to Tina Hoelzgen for her professional input on the topic of caretaking.

