Enhancing video search & discovery in a Rails application by using Whisper and ChatGPT

Building a reliable search for a web application is hard. Building it for a video-based platform is even harder. For Medmile, a German platform offering bite-sized video courses for doctors, we relied on descriptions created by the lecturers who recorded the courses to power search and discovery.
The problem: The lectures were focused on top-notch video content and not on writing extensive descriptions. Thus, the real content, the information we needed for the search engine to offer meaningful results, was ‘hidden’ in the course itself, in the audio track, to be precise.
Whisper and GPT to the rescue.
The general idea is simple: We transcribe the videos using Whisper, use GPT to generate summaries of its content, and calculate embeddings we can use for search and discovery.
Let’s have a look at the process:
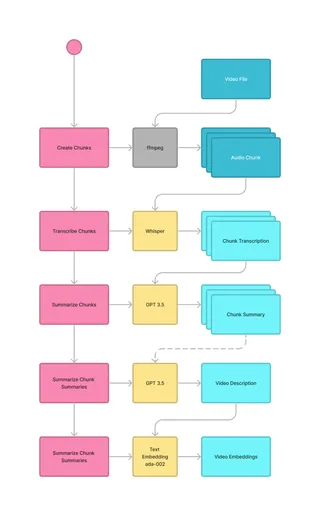
Transcribing the video
To transcribe the video, we first have to extract the audio track. Since we cannot transcribe the whole track at once, we split it into parts, creating chunks reliably small enough to be processed by OpenAI’s Whisper API.
Generating these chunks can easily be done with FFmpeg, in this case, used in a custom video processor hooked into ActiveStorage:
rubydef process
filename = blob.filename
new_filename = ActiveStorage::Filename.new("#{filename.base}.flac")
tempfile_pattern = "#{Dir.tmpdir}/#{new_filename.base}-%02d#{new_filename.extension_with_delimiter}"
blob.open tmpdir: Dir.tmpdir do |file|
system(
self.class.ffmpeg_path, "-y",
"-i", file.path,
"-vn",
"-f", "segment",
"-segment_time", "200",
"-acodec", "flac",
tempfile_pattern,
exception: true
)
end
# ...
endThese chunks can then be sent to Whisper using the Ruby OpenAI Gem.
rubydef client
@client ||= OpenAI::Client.new
end
def transcribe(tempfile)
response = client.audio.transcribe(
parameters: {
model: "whisper-1",
file: tempfile
})
response['text'] or raise "No text in transcription response..."
endInstead of just combining these chunks as raw text, we use GPT to generate summaries, both to make sure to stay within OpenAI’s limits but also to generate descriptions that could eventually be shown to the user as a more extensive description of the video. To allow implementation of our search functionality, we calculate the embeddings on the video summary and store it with the video, using Neighbor, a gem providing nearest neighbor search for Rails and Postgres.
rubydef generate_summary(text)
response = client.chat(
parameters: {
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: "Please summarize in maximum 850 characters:\\n#{text}\\n\\nSummary:"}],
temperature: 0.3,
})
response.dig("choices", 0, "message", "content") or raise "No text in API response: #{response}"
end
def calculate_embeddings(text)
response = client.embeddings(
parameters: {
model: "text-embedding-ada-002",
input: text
}
)
response.dig("data", 0, "embedding") or raise "No embedding in API response: #{response}"
end
def summarize(video)
summaries = []
summaries = video.raw_transcriptions.map do |transcription|
generate_summary(transcription)
end
video.gpt_summary = generate_summary(summaries.join(" "))
video.gpt_summary_embedding = calculate_embeddings(video.gpt_summary)
endStoring vectors
The Neighbor readme on Github offers a good explanation of how to use the gem, but for the sake of completeness, here are the few lines you need to store vectors:
rubyclass AddEmbeddingsToCoursesAndVideos < ActiveRecord::Migration[7.0]
def change
enable_extension "vector"
add_column :videos, :gpt_summary_embedding, :vector, limit: 1536
end
end
class Video < ApplicationRecord
has_neighbors :gpt_summary_embedding, normalize: true
self.filter_attributes += [ :gpt_summary_embedding ]
# ...
endWith Euclidean distance, we would not need normalized vectors, but since we are still experimenting, we decided it wouldn’t hurt to add that flag.
Using calculated embeddings for search
To perform a search based on a user query, we calculate the embeddings on the query using the same methods used for calculating embeddings on the video summaries. Then, we use these embeddings to look for the nearest neighbors within a set distance.
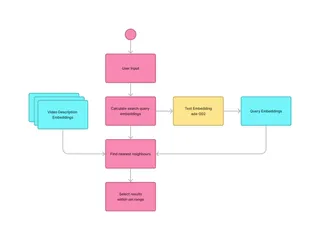
Thanks to Neighbor, this is done quite easily (at least in this simplified example):
rubyMAX_DISTANCE = 0.55
embeddings = generate_summary(query)
@ai_results =
Video.nearest_neighbors(:gpt_summary_embedding, embeddings, distance: "euclidean")
.limit(10)
.to_a
.select { |result| result.neighbor_distance < MAX_DISTANCE }The results are already ordered by distance to the query, so in theory, the best match should also be the first in the list. As usual, when it comes to AI, you have to experiment with real data and real queries to fine-tune things like maximum distance, as well as play with the queries used to generate the summaries.
Conclusion
We just released this function for registered users. Being in beta does not replace the ‘classic’ search function but rather provides an enhancement, displayed in an additional section when results seem to be good (a.k.a. close) enough, clearly marked as ‘AI results’.
First real user feedback is overwhelmingly positive, and we’ll continue working on enhancing the search function itself and using the generated video summaries to provide helpful support for lecturers in the form of AI-generated suggestions when it comes to writing video descriptions.
Do you have a project that would benefit from utilizing AI to support users and lead them to the right content? Don’t hesitate to get in touch with us.

