AI Glossary

Intro
This Blog post aims to provide a basic overview of the concepts and buzzwords in the AI realm. This is not a technical deep dive or a blog post that explores nuances of different concepts. This blog post introduces each concept or term with a definition or description, followed by examples or additional context. Lastly, links to further resources are provided for those interested in delving deeper.
Firstly, I would like to provide additional information on the three overarching concepts of the blog post. These concepts are AI (Artificial Intelligence), ML (Machine Learning), and generative AI. The following Venn diagram shows the relationship between these concepts. AI and ML are often used interchangeably, but ML is a subset of AI. So, not everything we call AI is based on ML, but everything based on ML can be called AI. The topic of generative AI mainly uses machine learning concepts, but there are examples of generative AI that are not based on ML.
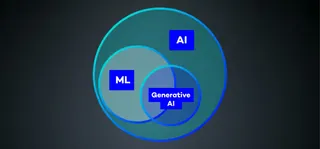
AI (Artificial Intelligence)
AI describes solving tasks or problems by computers/machines, which require a form of human-like intelligence.
Examples:
Image recognition
Chess Engines
Further definition:
ML (Machine Learning)
ML is a subfield of AI that describes the development of solutions for tasks or problems by computers/machines using data and algorithms without a programmer explicitly specifying the solution path through program code.
Use cases include:
Natural language generation
Image recognition
Autonomous driving
Further definition:
NN (Neural Network)
Neural Networks are a computer architecture that is inspired by the human brain. Neural Networks are a core principle of machine learning. They consist of interconnected nodes (neurons). Neural networks typically consist of an input layer, one or more hidden layers, and an output layer. Neural networks process inputs using a variety of mathematical operations and subsequently produce an output.
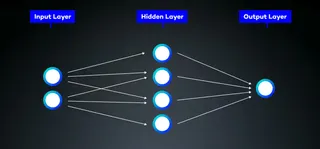
Further definition:
DL (Deep Learning)
DL is a machine learning subfield based on neural networks with multiple input, hidden and output layers. Various transformations and feature extractions can be performed in the different layers to recognize more complex patterns.
Use cases include:
Natural language processing
Image recognition
Recommender systems
Further definition:
Model
A model in the context of neural networks refers to the structure of the layers, activation functions, and nodes with associated weights and biases. The model is created and optimized through machine learning by learning from input data and recognizing patterns. The goal of a model is to provide predictions based on input data.
Well-known models include:
AlexNet (Computer Vision Model)
AlphaZero (Chess Engine based on Machine Learning)
Example: I want to make statements based on pictures as input, determining whether the image contains an astronaut or an alien. An abstract model could look like this. We divide the properties of astronauts and aliens into "all" and "some". When the model receives the first image, it guesses because it has no prior data. Let's say it guessed “astronaut”. The Model now thinks all astronauts in the world will look like this. So, every property of the image is put in the “all” category. The model gets a different picture and will most likely say alien, even if it is an astronaut, because the new image will not check everything in the “all” properties. The model then updates itself and puts properties shared by both astronauts in “all” and the rest in “some”. This process will repeat for the whole training dataset so that the Model can adjust what are “all” and what are “some” properties for astronauts and aliens.
Additional information:
Weights, Activation function, and Biases
Weights are numeric values representing the strength of connections between nodes in a neural network. They determine the extent to which the output of one node influences the subsequent node.
Activation functions are Non-Linear Functions that calculate the output value of a neuron. Based on the output value, the neuron will be activated or not. For the calculation, an activation function sums all inputs and weights connected to the neuron and adds a bias.
Biases are numeric values independent of the previous layer. Each node has its bias value and can control the activation of that node by shifting the activation function right or left. This enables more flexibility for the neural network.
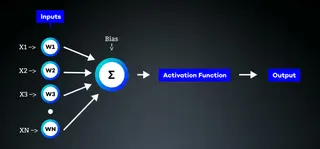
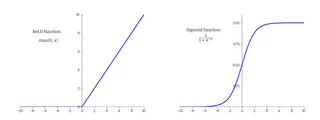
Additional information:
Model Parameter
Model Parameters are a model's internal values learned from the input data during training. In neural networks, parameters include weights and biases. These parameters are optimized to enable the neural network to make accurate predictions about the input data.
Additional information:
Training/Learning
Training/Learning describes the iterative process in which data is passed to a neural network. After each iteration, the learnable parameters of the neural network are adjusted to achieve an optimal solution for the given problem.
For training models, a dataset is required. There are different strategies for using this data for training. However, using different data for training and validating the model is essential.
Additional information:
Hyperparameter
Hyperparameters are values provided to the model from the outside to make adjustments that can influence the learning process and its performance, among other things. The optimal settings for a model are usually determined through systematic tuning of the parameters or experimentation.
The learning rate is one Hyperparameter that can be set; it can specify how much the weights between the neural network nodes are adjusted after each iteration.
Additional information:
AGI (Artificial General Intelligence)
AGI is also referred to as strong AI. An AGI can independently learn new problem-solving strategies that are not explicitly included in its original model or training data, and it can handle various tasks in different contexts.
So far, all the AI systems we have developed are not AGI. There are different assessments regarding when and whether it will be possible to create an AGI.
Further definition:
Narrow/Weak AI
Narrow/Weak AI refers to systems designed to perform specific tasks. These systems rely on their training data and underlying model and cannot independently learn new skills or solve problems beyond their original scope.
For example, an AI like AlphaZero excels at chess better than any human player and does not know how to play Go or Tic-Tac-Toe. There are systems, such as in a self-driving car, where multiple weak AI's work together. However, each AI system is only responsible for its specific domain.
Further definition:
Big Data
Big Data refers to large amounts of data, typically internet, mobile, health, or traffic. These data sets often exceed the storage capacity of standard databases and require specialized solutions. This data is used as the basis for data preprocessing to train models.
Further definition:
Bias
Note: This concept of Bias has nothing to do with the biases in the scope of the nodes in a neural network!
Bias describes the process by which the outputs of AI systems can be based on certain assumptions or prejudices. Various factors can contribute to the emergence of bias in an AI system, such as the training data, the model used, and the evaluation of the outputs. Bias can distort the results of an AI system and lead to unequal treatment of specific individuals or groups.
For example, if you feed an AI system with pilot data and then ask it to define the characteristics of a good pilot, it will likely describe a white male person because these characteristics apply to many pilots. However, humans know these are different from the criteria we seek when describing a pilot.
Additional information:
https://brie.berkeley.edu/sites/default/files/brie_wp_2018-3.pdf
https://hbr.org/2019/10/what-do-we-do-about-the-biases-in-ai
Alignment
Alignment describes the process of evaluating the outputs of an AI according to predefined values, usually ethical or social values. This feedback can be used to ensure that the model operates within this value framework.
OpenAI has employed many individuals in precarious working conditions in the so-called Global South for the alignment of ChatGPT, who evaluate outputs and prompts based on the following values defined by OpenAI:
Truthfulness
Harmlessness
Helpfulness
An example of the negative consequences that can occur with AI systems when they lack alignment is demonstrated by Microsoft's chatbot Tay. Within a few hours, the chatbot became radicalized and had to be shut down after 16 hours.
Additional Information:
Reinforcement Learning
Reinforcement Learning describes a form of model training where the model can decide how to fulfill a task. The model receives rewards or punishments at specific time points or after actions. The goal of the model is to obtain the highest possible rewards.
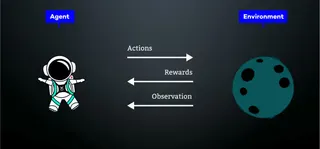
Use cases include:
Self-driving cars
Gaming
Resource management
Additional Information:
Supervised Learning
Supervised Learning describes a form of model training where datasets consisting of pairs of input and corresponding output data are used. Based on the input, the model makes a prediction and then compares it to the output data.
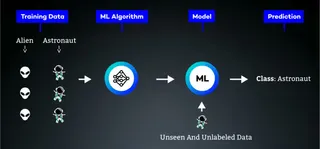
Use cases include:
Classification problems
Regression problems
Anomaly detection
Additional information:
Unsupervised Learning
Unsupervised Learning describes a form of model training where no predefined goals for the results are set. The aim is to find patterns, structures, or relationships based on the given input data.
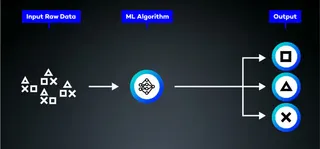
Use cases include:
Clustering problems
Anomaly detection
Recommender systems
Additional information:
Overfitting
Overfitting is a problem that can occur during training when the model becomes too closely adapted to the training data, losing the ability to make accurate predictions for new data.
For example, let's say we want a model that can determine if there is an astronaut in the input image. We train the model with 10,000 images and find that after training, the model can almost accurately predict whether there is an astronaut with nearly 100% accuracy. However, when we use our validation dataset, the model only achieves an accuracy rate of 55%. Essentially, the model is guessing whether it is an astronaut or not. The model has likely failed to learn to recognize what an astronaut is but instead has memorized the training data.
Additional information:
Fine Tuning
Fine Tuning, often referred to as transfer learning, describes adapting a pre-trained model to improve its performance in a specialized subset of the problem or to solve a new task closely related to the original one. This eliminates the need to completely retrain a model.
OpenAI's GPT model can be used as a text recognition and generation base model. Based on this model, additional datasets, such as internal product descriptions, can be added, and the GPT model can be fine-tuned to deliver better results for the new datasets.
Additional information:
Prompt / Prompt Engineering
Prompt is the user input, usually a few words or a sentence, that describes what a generative AI should produce.
Prompt Engineering involves optimizing prompts, i.e., determining which prompts effectively achieve the desired results. Important aspects include providing context to the prompt and experimenting with different prompts.
Additional information:
Generative AI
Generative AI describes AI systems that generate various outputs using user inputs (prompts). Use cases include text, code, image, video, or music generators.
Well-known generative AI systems include:
ChatGPT (Text)
Midjourney, Stable Diffusion, DALL-E (Image)
Murf, Lovo, Whisper (Voice)
Additional information:
Clustering
Clustering is a problem in the AI context where one searches for relationships or patterns in large datasets that overarching clusters can describe. Unsupervised learning is commonly used for this type of problem.
In this process, algorithms calculate the similarity between data points and create a network of data points where the similarity is represented by distance. This allows for the identification of groupings (clusters). A popular algorithm to detect clusters is the K-Means Algorithm.
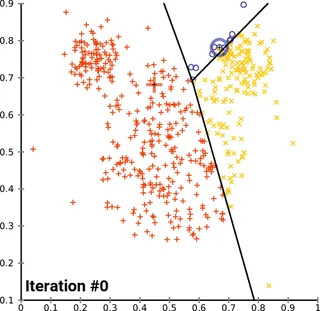
Additional Information:
Image reference:
https://commons.wikimedia.org/wiki/File:K-means_convergence.gif
Classification
Classification is a problem in AI where the input is mapped to an output value from a set of defined output values. The outputs can be discrete classes such as "Yes/No," "Categories," or "Labels." Supervised learning is commonly used for this type of problem.
The example given in the model section is a typical example of a classification problem. Pictures that can be mapped into distinct classes.
Additional information:
Regression
Regression is a type of problem in the AI context where the output values are continuous and numerical. The goal is to make predictions in the form of numerical output values based on the input. Supervised learning is commonly used for this type of problem.
An example of regression is predicting house prices based on square meters, number of rooms, and the city. A model trained on this dataset should be able to predict the price for a new data point given the input of square meters, number of rooms, and the city.

Additional information:
Sentiment Analysis
Sentiment Analysis describes identifying a text's sentiment, attitude, or evaluation.
Use cases include:
Market research
Monitoring social media
Political analysis
Additional information:
Hallucination
Hallucination is a process in which a generative AI produces an output unsupported by the training data or contradicts known facts.
Other terms for the concept of hallucination are:
confabulation
delusion
Some even call it: bullshitting.
There are different reasons why an output can be described as a hallucination:
Data quality of the training data: There are attacks on LLMs where you poison the training data with wrong information
Lack of context, e.g., there are two Persons with the same name relevant to the given prompt, and the model mixes up data from the two persons.
Additional information:
Language Models / Large Language Models
Language models calculate the distribution and probabilities of a word or word sequences based on the previous context or the previous sequence. They enable computers/machines to process and generate natural language.
Large language models are a particular class of language models with a huge number of parameters and are trained on a large amount of data. Large language models can, therefore, recognize more complex language patterns and capture larger contexts.
Well-known models include:
GPT
N-Gram Model
LTST Model (Long Term Short Term)
LaMDA
Llama
Additional information:
Transformer
Transformers are a computer architecture used in neural networks to transfer one sequence of characters to another. Transformers are used in computer systems for natural language processing.
Transferring one sequence of characters to another is the classical approach in language translation. A simple look-up table cannot be used in translation because words in different languages often have multiple meanings, and sentence structures vary between languages.
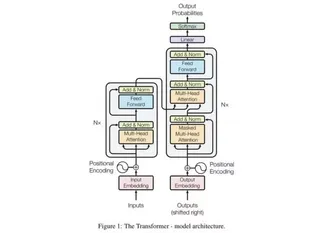
Additional Information:
Image reference:
https://arxiv.org/abs/1706.03762 Figure 1: The Transformer - model architecture.
GPT (Generative Pre-trained Transformer)
GPT is the most well-known language model used by the ChatGPT application developed by OpenAI. It can process prompts and generate text as output. The generated text includes both natural language and computer code.
Additional information:
Token
Tokens are representations of strings of characters (words or subwords) used to convert natural language into a machine/computer-understandable system.
The tokenization used by OpenAI for words and punctuation in the English language yields the following:
1 token ~= 4 chars in English
1 token ~= ¾ words
100 tokens ~= 75 words

Additional information:
NLP (Natural Language Processing)
NLP (Natural Language Processing) is a branch of AI development that focuses on enabling machines/computers to process natural/human language.
Use cases of NLP include:
Speech recognition
Translation
Sentiment analysis
Additional information:
NLG (Natural Language Generation)
NLP is a branch of AI development that focuses on enabling machines/computers to generate natural/human language and thus communicate.
Areas of NLG (Natural Language Generation) include:
Chatbots
Voice assistants
Content generation
Additional information:
OpenAI
OpenAI is a company based in the USA that is engaged in developing and researching AI systems. The stated goal of OpenAI is to create AGI (Artificial General Intelligence). Well-known products from OpenAI include ChatGPT and DALL-E.
Additional information:


{kind=link}